- Opublikowano dnia
Praktyczne zastosowanie aystenta AI. Integracja API GPT od OpenAI z aplikacją webową do analizy danych
- Autorzy

- Imię
- Martin Szerment
W dzisiejszym dynamicznym świecie technologicznym, integracja inteligentnych asystentów, takich jak GPT-4, z aplikacjami webowymi staje się coraz bardziej popularna. GPT-4, opracowany przez OpenAI, oferuje potężne możliwości analizy danych, które mogą znacząco poprawić funkcjonalność i wartość aplikacji webowych. W tym artykule przedstawimy krok po kroku, jak podłączyć API GPT-4 do aplikacji webowej w celu analizy danych.

Oczywiście, podłączenie tego typu asystenta GPT lub innego dużego modelu językowego (LLM) opartego na zewnętrznych serwerach powoduje, że aplikacja webowa, z której korzysta użytkownik końcowy, musi mieć dostęp do zewnętrznego internetu.
Modele GPT od wersji 3.5 i wyższych są udostępniane poprzez API, ale znajdują się wyłącznie na serwerach firmy OpenAI.
Lokalnym rozwiązaniem są jedynie model GPT w wersji 2.0, dostępne w trzech wersjach wagowych, z największą wersją XL ważącą około 6 GB. Model ten jest jakościowo słabszy w porównaniu do wersji 3.5, jednak do prostych zadań się nadaje. Warto nadmienić, że obsługuje wyłącznie język angielski.
Innym rozwiązaniem jest skorzystanie z modeli LLM z strony: https://huggingface.com/
które już możemy stosować lokalnie i są trenowane pod różne zastosowania.
O wdrażaniu lokalnych modeli językowych (LLM) i bezpieczeństwie przekzywanych danych na zewnętrzne serwery napiszę w kolejnym artykule, a teraz przedstawię prosty sposób na wdrożenie asystenta GPT poprzez API OpenAI, korzystając z frameworka Flask ze względu na szybkie tworzenie w nim API aplikacji.
Przedstawię także praktyczne zastosowanie asystenta GPT na konkretnym przykładzie, mianowicie na systemie Omnimes tworzonym przez firmę Multiprojekt.
Omawiany system służy do monitorowania i realizacji produkcji w fabrykach i zakładach produkcyjnych.
Krok 1: Rejestracja i Uzyskanie Klucza API
Pierwszym krokiem jest rejestracja na platformie OpenAI i uzyskanie klucza API. Klucz ten będzie niezbędny do uwierzytelnienia się i komunikacji z serwerem OpenAI.
- Zarejestruj się na stronie OpenAI.
- Po zalogowaniu, przejdź do sekcji "API" i utwórz nowy klucz API.
- Zanotuj klucz API, który będzie używany w Twojej aplikacji.
Krok 2: Przygotowanie Środowiska Aplikacji Webowej
Aby zintegrować API GPT-4, potrzebujesz środowiska programistycznego dla swojej aplikacji webowej. W tym artykule użyjemy przykładu w Pythonie z frameworkiem Flask.
Instalacja Flask
Jeśli nie masz jeszcze zainstalowanego Flaska, możesz go zainstalować za pomocą pip:
pip install Flask
Tworzenie Podstawowej Aplikacji Flask
Stwórz nowy plik o nazwie app.py i dodaj podstawowy kod aplikacji Flask:
from flask import Flask, request, jsonify
import openai
app = Flask(__name__)
# Klucz API OpenAI
openai.api_key = 'TWÓJ_KLUCZ_API'
@app.route('/analyze', methods=['POST'])
def analyze():
data = request.json
prompt = data.get('prompt')
if not prompt:
return jsonify({'error': 'Brak promptu'}), 400
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=150
)
return jsonify(response.choices[0].text)
if __name__ == '__main__':
app.run(debug=True)
Krok 3: Konfiguracja i Wywoływanie API GPT-4
Konfiguracja API
W powyższym kodzie, skonfigurowaliśmy klucz API OpenAI oraz endpoint /analyze, który przyjmuje zapytania POST z danymi JSON zawierającymi prompt do analizy.
Przykładowe Wywołanie API
Aby przetestować naszą aplikację, możemy użyć narzędzia takiego jak Postman lub curl. Oto przykład użycia curl do wysłania zapytania:
curl -X POST http://127.0.0.1:5000/analyze \
-H "Content-Type: application/json" \
-d '{"prompt": "Przykładowy tekst do analizy"}'
Aplikacja powinna zwrócić odpowiedź zawierającą analizę promptu wykonaną przez GPT-4.
Krok 4: Integracja z Aplikacją Webową
Następnie, musimy zintegrować nasz endpoint z frontendem aplikacji webowej. Możemy to zrobić za pomocą AJAX w JavaScript.
Przykład Integracji z Frontendem
W pliku HTML dodajemy formularz do wprowadzenia tekstu oraz przycisk do wysłania danych do naszego endpointu:
<!doctype html>
<html lang="pl">
<head>
<meta charset="UTF-8" />
<title>Integracja GPT-4</title>
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
</head>
<body>
<h1>Analiza Tekstu z GPT-4</h1>
<textarea id="prompt" rows="10" cols="50"></textarea>
<br />
<button id="analyze-button">Analizuj</button>
<h2>Wynik:</h2>
<pre id="result"></pre>
<script>
$(document).ready(function() {
$('#analyze-button').click(function() {
const prompt = $('#prompt').val();
$.ajax({
url: '/analyze',
method: 'POST'.
contentType: 'application/json',
data: JSON.stringify({ prompt: prompt }),
success: function(response) {
$('#result').text(response);
},
error: function(error) {
$('#result').text('Wystąpił błąd: ' + error.responseJSON.error);
}
});
});
});
</script>
</body>
</html>
Praktyczne zastosowanie asystenta AI na przykładzie systemu realizacji produkcji OMNIMES
Poniższy przykład omawia tylko samo działanie asystenta GPT w już działającym systemie.
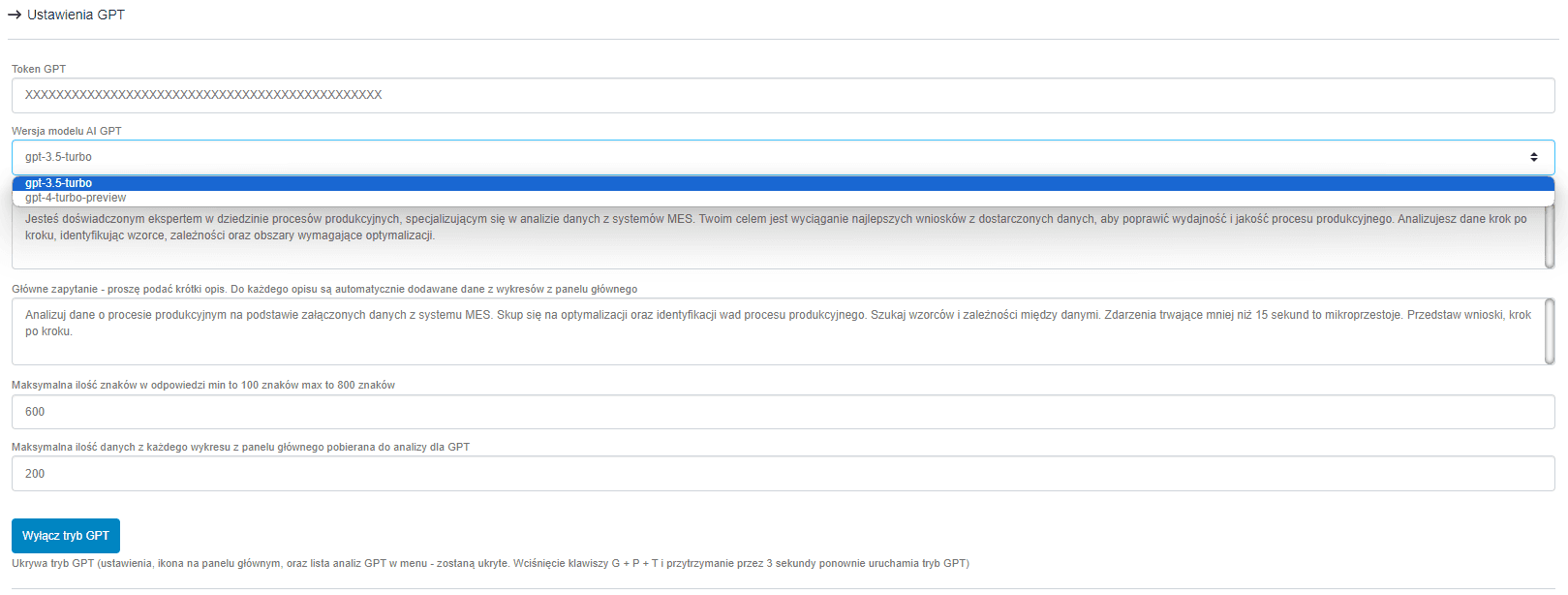
Powyższe zdjęcie przedstawia opcje ustawień asystenta. Pierwsze pole wymaga od użytkownika podania tokena API z OpenAI. W tym przykładzie użytkownik ma do wyboru dwa modele: wersję 3.5 i 4. Osobiście doradzam korzystanie z wersji 3.5, gdyż jest dużo tańsza. Główna różnica polega na tym, że wersja 4 lepiej sprawdza się w dłuższych konwersacjach. W tym przykładzie będziemy zadawać asystentowi jedno pytanie z przekazanymi danymi produkcyjnymi w celu ich szybkiej analizy.
Kolejne pola są dość istotne. W pierwszym podajemy charakterystykę roli, w jaką ma się wcielić asystent. Drugie pole to główne zapytanie, które ma być realizowane. Do każdego z zapytań są dołączone dane pobrane z podsumowania znajdującego się na pulpicie głównym systemu.
Kolejne pola to pola ograniczające długość odpowiedzi asystenta oraz ilość przesłanych danych z podsumowania.
Fajnym trybem jest możliwość ukrycia trybu asystenta GPT w całym systemie.
Zapytanie do asystenta odbywa się poprzez przesłanie głównego zapytania ustawionego we wcześniejszej konfiguracji oraz załączenie danych pochodzących z podsumowania, które użytkownik sam może stworzyć. Poniżej znajdują się zdjęcia z panelu głównego:
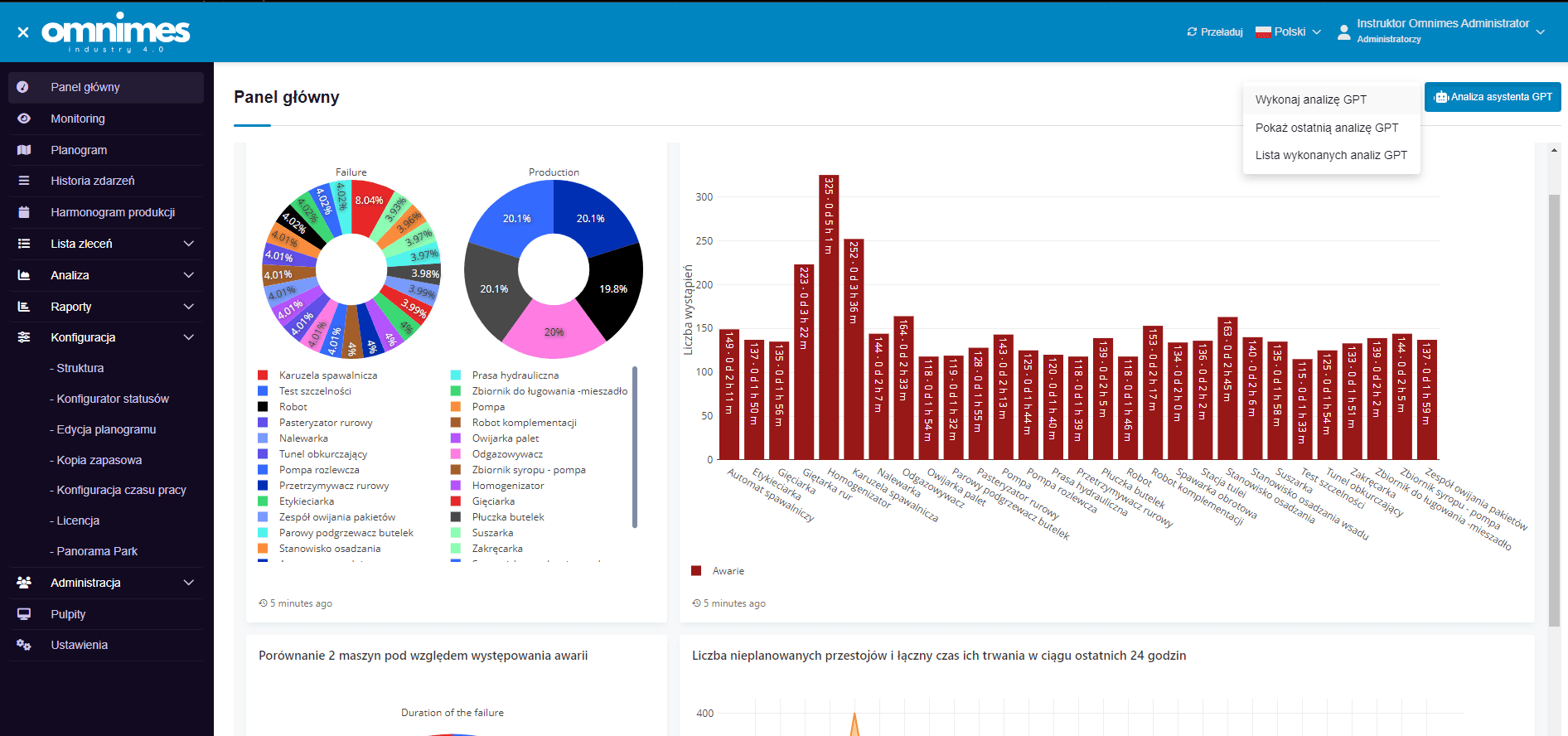
W prawym górnym rogu widoczny jest przycisk do wykonania analizy, dzięki któremu dosłownie za jednym kliknięciem uzyskamy analizę przesłanych danych widocznych na wykresach. Poniżej znajduje się rezultat analizy.
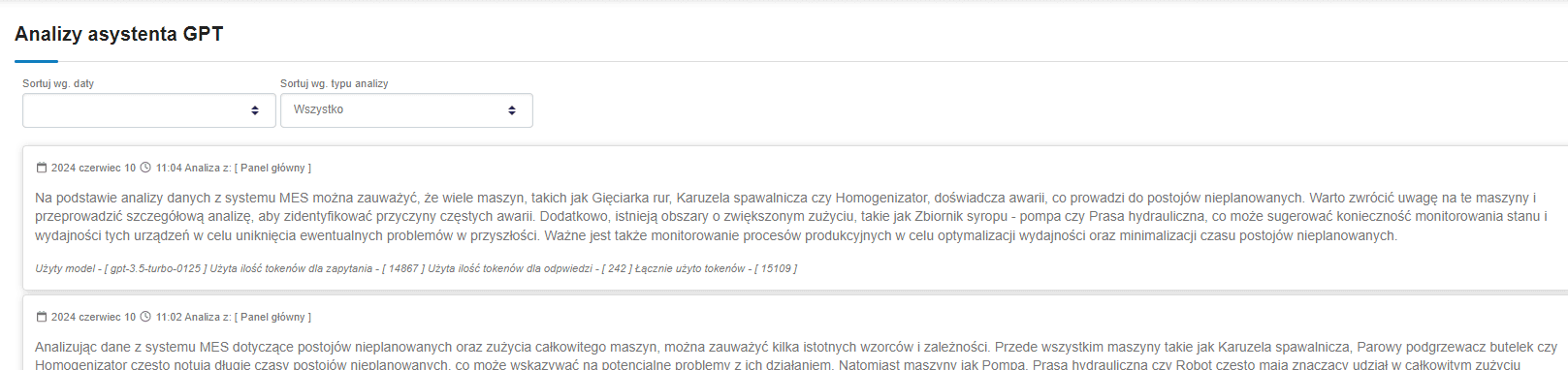
Fajnym zastosowaniem jest możliwość przeglądania wykonanych analiz przez asystenta, a także uzyskanie informacji o użytym modelu i liczbie wykorzystanych tokenów.
Podsumowanie
Integracja API GPT-4 z aplikacją webową pozwala na wykorzystanie zaawansowanych funkcji analizy danych, co może znacznie zwiększyć wartość i funkcjonalność Twojej aplikacji. Proces ten obejmuje uzyskanie klucza API, skonfigurowanie aplikacji backendowej i zintegrowanie jej z frontendem. Dzięki temu użytkownicy Twojej aplikacji będą mogli korzystać z potężnych możliwości analitycznych oferowanych przez GPT-4.
Jednakże, wraz z korzystaniem z tego typu rozwiązań, nasuwa się pytanie: co z polityką bezpieczeństwa danych?
Odpowiedź jest prosta: trzeba wziąć pod uwagę, że do takiego asystenta przesyłamy tylko fragment danych, które są wyciągnięte z większej całości, a pojedynczy fragment ma niewielką wartość w skali globalnej.
Chociaż tłumaczenie się takim argumentem może być skuteczne, to jednak może stanowić barierę nie do przebycia w stosunku do polityki bezpieczeństwa niektórych przedsiębiorstw.
Dlatego istnieje możliwość wdrożenia modelu LLM lokalnie, o czym napiszę w kolejnym artykule.
← Powrót do bloga