
Jednym z częściej zadawanych pytań w projektach MES jest: jak zbudować dashboardy analityczne na danych, które żyją w MongoDB, bez przepisywania backendu do bazy SQL? W OmniMES używamy do tego Redash — z dwóch powodów. Po pierwsze, Redash potrafi konsumować REST API jako źródło danych. Po drugie, ma mechanizm Query Results, który pozwala pisać pełny SQL na wyniku dowolnego wcześniejszego zapytania.
W praktyce daje to kombinację, która dla wielu wdrożeń MES okazuje się przełomowa: siła SQL (JOIN, CTE, funkcje okienne) na danych z nierelacyjnej bazy, bez zmian w warstwie produkcyjnej. Artykuł pokazuje krok po kroku, jak to uruchomić — od konfiguracji Redasha, przez zapytanie do REST API OmniMES, po SQL wyliczający trend wibracji i gotową wizualizację na dashboardzie.
Dlaczego akurat Redash
OmniMES generuje dziesiątki tysięcy dokumentów dziennie — telemetria maszyn, stan zleceń produkcyjnych, alarmy, liczniki energii, logi OEE. Składujemy to w MongoDB, ponieważ schemat danych z różnych maszyn jest niejednorodny (inna struktura z tokarki, inna z pieca hartowniczego, inna z kompresorowni), a MongoDB radzi sobie z taką zmiennością zdecydowanie lepiej niż tradycyjne RDBMS.
Problem pojawia się w warstwie prezentacji. Standardowe dashboardy OmniMES pokrywają około 80% typowych potrzeb — OEE, mikroprzestoje, raport zmianowy, zużycie energii. Pozostałe 20% to wymagania specyficzne dla danego zakładu: analiza wibracji z trendem, korelacja jakości z temperaturą formy, rozkład mikroprzestojów w funkcji operatora. Dla tych przypadków nie chcemy rozwijać dashboardu per klient — wolimy dać narzędzie self-service, w którym analityk lub inżynier procesu sam napisze zapytanie.
Redash spełnia trzy kluczowe wymagania:
- Jest open source (BSD-2) — można go hostować we własnej infrastrukturze obok OmniMES, co jest istotne dla klientów pracujących w trybie on-premise lub w izolowanych sieciach OT.
- Obsługuje dziesiątki źródeł danych — PostgreSQL, MongoDB (ograniczone), BigQuery, ClickHouse, Presto, a także JSON/URL i Query Results.
- Ma prosty mechanizm udostępniania — dashboard można opublikować jako publiczny link z tokenem albo osadzić w iframe po stronie OmniMES lub w intranecie klienta.
Architektura rozwiązania
OmniMES backend (Node.js / Python) ──► MongoDB
│
▼
REST API: /data/dataBi/?server=0&line=0&machine=0&...
│
▼
┌──────────────────────── Redash ────────────────────────┐
│ │
│ Data Source: JSON ──► Query 56: surowe dane (raw) │
│ │ │
│ ▼ │
│ Data Source: Query Results ──► Query 57: SQL + trend │
│ │ │
│ ▼ │
│ Visualization: scatter + linia trendu │
│ │ │
│ ▼ │
│ Dashboard: "Monitoring wibracji CNC" │
│ │
└────────────────────────────────────────────────────────┘
Kluczowa idea: REST API OmniMES jest pierwszą warstwą zapytania, a SQL — drugą. MongoDB sama nie mówi SQL, ale po tym jak endpoint REST zwróci JSON w tabularnej formie, Redash traktuje go jak zwykłą tabelę, na której możemy zapiąć dowolny SQL SQLite (silnik, którego Redash używa do Query Results).
Krok 1 — Skonfiguruj źródła danych w Redash
Logujemy się do Redasha jako administrator i przechodzimy do Settings → Data Sources. Potrzebujemy dwóch źródeł:
- JSON — do odpytywania REST API OmniMES.
- Query Results — wbudowane, "meta-źródło" pozwalające pisać SQL na wynikach innych zapytań.
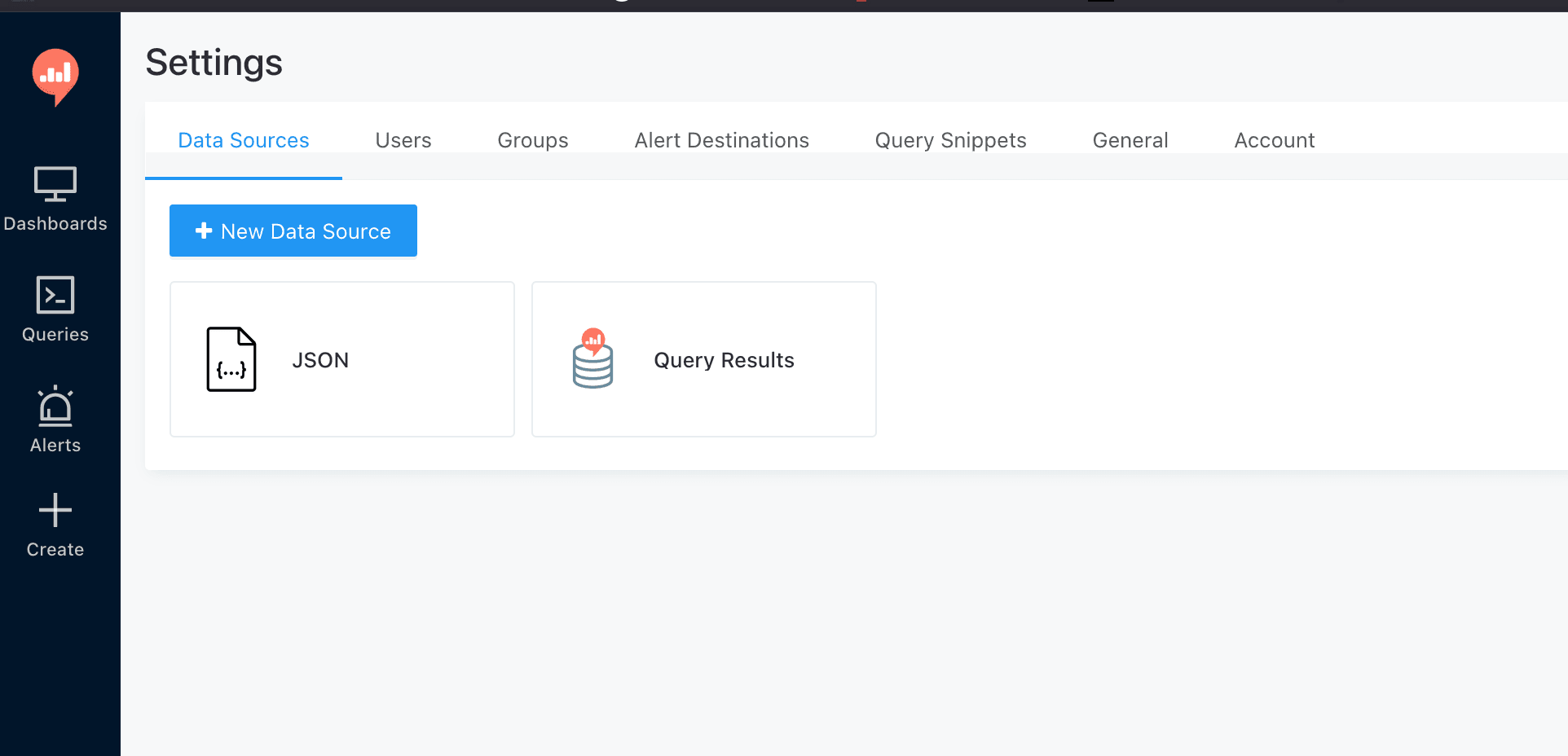
Klikamy + New Data Source, wybieramy JSON i nadajemy nazwę (np. OmniMES REST). Pole konfiguracyjne jest minimalistyczne — nie potrzebujemy host/port, bo pełny URL podamy w treści każdego zapytania. Następnie dodajemy drugie źródło typu Query Results. To wbudowany silnik SQLite, który indeksuje wyniki wszystkich wcześniejszych zapytań w Redashu i udostępnia je jako tabele o nazwach query_<id>.
Krok 2 — Zapytanie bazowe: pobranie danych z REST API
Tworzymy nowe zapytanie, wybieramy jako źródło OmniMES REST i w polu zapytania piszemy w formacie YAML, który Redash rozumie dla JSON source:
url: http://api:8091/data/dataBi/?server=0&line=0&machine=0&type_data=0&type_event=1&period=1h
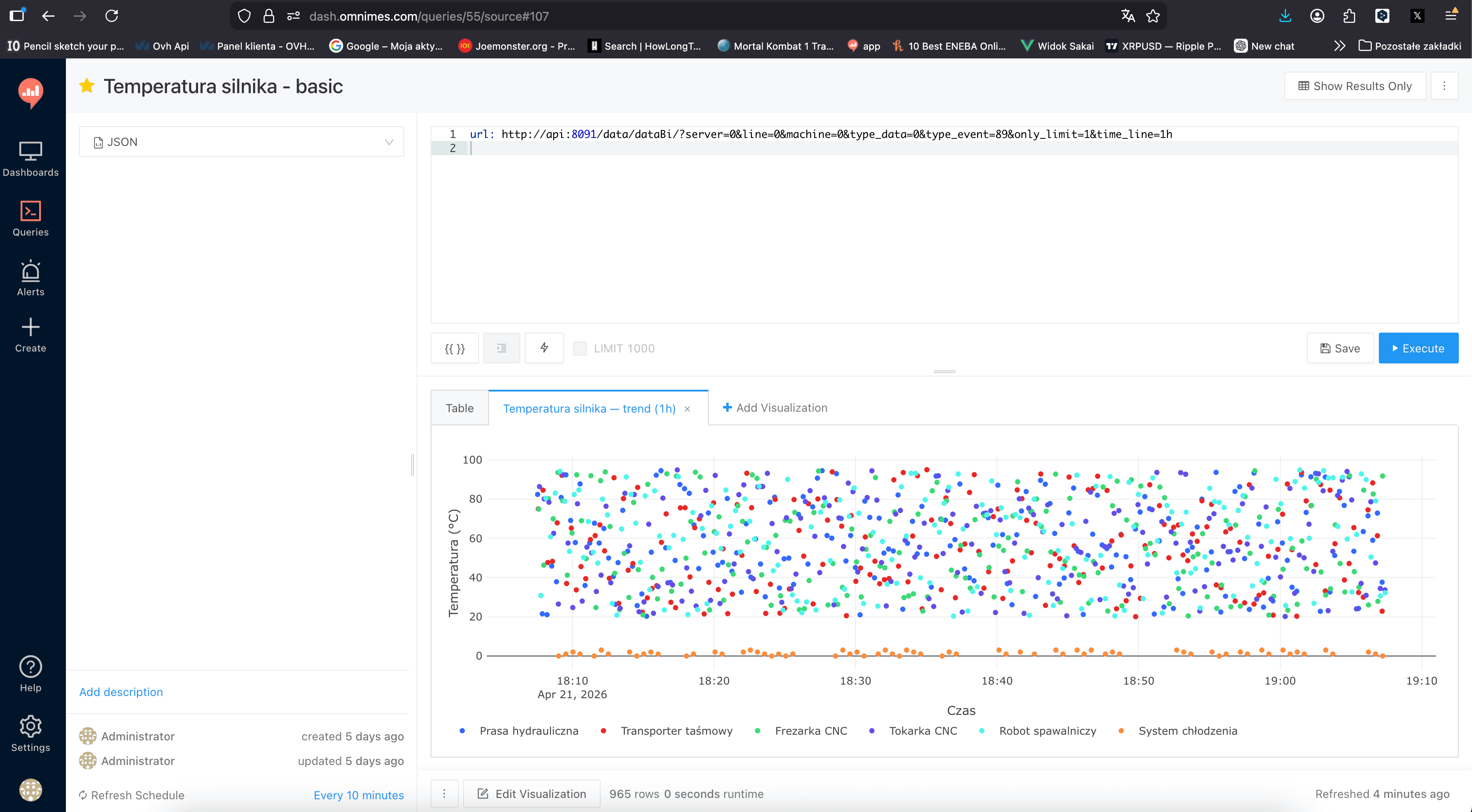
Redash wykona request, sparsuje odpowiedź JSON do tabeli i przypisze zapytaniu wewnętrzne ID (np. 56). To ID będzie nam potrzebne w kolejnym kroku.
Parametry w URL są kluczowe:
server— identyfikator instancji OmniMESline— linia produkcyjnamachine— identyfikator maszyny (0 = wszystkie)type_data— rodzaj danych (pomiar, zdarzenie, stan)type_event— klasa zdarzenia (wibracje, temperatura, prąd, itd.)period— okno czasowe zwracane przez API
W realnym wdrożeniu parametryzujemy to w Redashu przez składnię {{machine}} i {{period}}, co daje użytkownikowi dashboardu kontrolę nad wyborem maszyny i zakresu czasu bez pisania SQL.
Zapisujemy zapytanie jako Poziom wibracji — basic i ustawiamy Refresh Schedule — w tym przypadku co 10 minut. Redash będzie periodycznie odpytywał API, cache'ował wynik i udostępniał go zarówno tej wizualizacji, jak i każdej innej, która z tego ID korzysta.
Krok 3 — SQL na wynikach: obliczenie trendu
Teraz tworzymy drugie zapytanie, tym razem na źródle Query Results. Odwołujemy się do wcześniejszego zapytania przez query_56 i nakładamy logikę SQL:
SELECT
bucket AS datetime_add,
COALESCE(
MAX(CASE WHEN name_machine = 'Tokarka CNC' THEN value END),
NULL
) AS tokarka,
COALESCE(
MAX(CASE WHEN name_machine = 'Frezarka CNC' THEN value END),
NULL
) AS frezarka,
MAX(CASE WHEN name_machine = 'Tokarka CNC' THEN trend END) AS tokarka_trend,
MAX(CASE WHEN name_machine = 'Frezarka CNC' THEN trend END) AS frezarka_trend
FROM (
SELECT
strftime('%Y-%m-%d %H:%M:', datetime_add) ||
printf('%02d', (CAST(strftime('%S', datetime_add) AS INT) / 30) * 30) AS bucket,
value,
name_machine,
AVG(value) OVER (
PARTITION BY name_machine
ORDER BY datetime_add
ROWS BETWEEN 5 PRECEDING AND 5 FOLLOWING
) AS trend
FROM query_56
)
GROUP BY bucket
ORDER BY bucket;

Co robi to zapytanie:
- Wewnętrzny SELECT przerzuca każdą próbkę do "kubełka 30-sekundowego" (
bucket) i oblicza ruchomą średnią z 11 sąsiednich próbek (5 przed, 5 po, bieżąca) — to jest nasza linia trendu. - Zewnętrzny SELECT pivotuje dane po maszynie (Tokarka CNC, Frezarka CNC), dzięki czemu dostajemy tabelę z kolumnami
datetime_add,tokarka,frezarka,tokarka_trend,frezarka_trend. - Używamy
strftime+printf(pełny SQLite), żeby precyzyjnie zaokrąglić timestamp do 30s — cenna technika, gdy chcemy kontrolować granularność wykresu niezależnie od tego, co zwraca REST API.
W tym momencie dzieje się rzecz najważniejsza. Dane fizycznie przyszły z MongoDB, ale my piszemy na nich pełny SQL z funkcją okienną AVG() OVER (PARTITION BY ... ROWS BETWEEN ...). Żadne natywne zapytanie Mongo (ani agregacje, ani $setWindowFields) nie dałoby nam tak czytelnej formy — a my dostajemy to za darmo, bo Redash uruchamia SQLite na swoim cache.
Krok 4 — Wizualizacja
Dwa style prezentacji, które najczęściej łączymy:
- Scatter plot — każda próbka surowa jako kropka (niebieska Tokarka CNC, czerwona Frezarka CNC).
- Linia —
tokarka_trendifrezarka_trendjako gładkie krzywe pokazujące kierunek.

Wyświetlone razem dają czytelny obraz: operator widzi szumy chwilowe (scatter) oraz jednocześnie kierunek, w którym dryfuje proces (trend). Dla działu UR to jest pierwszy sygnał, że łożysko albo prowadnica zaczyna pracować poza normą — jeszcze zanim przekroczy twardy próg alarmu.
W Redashu idziemy do Edit Visualization, wybieramy typ Chart, jako X column podajemy datetime_add, jako Y columns cztery pozostałe (wartości + trendy), ustawiamy styl points dla surowych i line dla trendów. Kolorujemy zgodnie z kolorystyką OmniMES (niebieski = pierwsza maszyna, czerwony = druga).
Krok 5 — Dashboard i udostępnianie
Zapytanie z wizualizacją pinujemy do dashboardu Monitoring CNC — wibracje. Dashboard w Redashu można:
- Udostępnić publicznym linkiem z tokenem — zewnętrzni użytkownicy widzą treść bez logowania do Redasha, ale link zawiera losowy token, więc nie jest odnajdywalny przez Google.
- Osadzić w iframe — na własnej stronie, w intranecie klienta albo bezpośrednio w widoku OmniMES.
- Udostępnić wewnętrznie — na podstawie ról w Redashu (np. operatorzy widzą tylko swoją linię).
Dodatkowo ustawiamy dashboard-level refresh co 10 minut — wszystkie widgety odświeżają się jednocześnie, a użytkownik ma świeży obraz bez ręcznego odświeżania.
Co to daje względem standardowych dashboardów OmniMES
Rola takiego rozwiązania nie jest "zamiast", tylko "obok" natywnych widoków OmniMES. Zalety są praktyczne:
- Pełne SQL na NoSQL bez migracji. CTE, JOIN między zapytaniami, funkcje okienne, window frames, agregacje — wszystko to na danych, które fizycznie mieszkają w MongoDB. Dla zespołu analitycznego to oszczędność tygodni pracy w porównaniu z pisaniem agregacji w pipeline MongoDB.
- Zero zmian w backendzie OmniMES. Każda nowa analiza to nowe zapytanie w Redashu — nie dotyka kodu produkcyjnego, nie wymaga deploymentu, nie łamie SLA.
- Self-service dla klienta. Inżynier procesu, analityk, lider zmiany — każdy buduje własne wykresy bez angażowania developerów. W projektach, w których to wprowadziliśmy, liczba zgłoszeń typu "poproszę kolejny raport" do naszego zespołu spadała o 60–80% w ciągu pierwszego kwartału.
- Wspólne repozytorium dashboardów. Redash trzyma wszystkie zapytania i dashboardy w jednym miejscu z kontrolą wersji (diff, rollback), tagami, kategoriami. Dzięki temu wiedza o tym, "jak policzyć OEE po zmianie" albo "gdzie jest raport jakości dla produktu X", nie rozjeżdża się między mailami i Excelami.
OmniEnergy — ten sam wzorzec, inny endpoint
OmniEnergy to moduł OmniMES dedykowany zarządzaniu efektywnością energetyczną (EMS zgodny z ISO 50001). Architektonicznie stosuje ten sam wzorzec: telemetria liczników prądu, gazu, sprężonego powietrza trafia do MongoDB, a udostępniana jest przez endpoint /data/energyBi/.
W Redashu budujemy dashboardy takie jak:
- Zużycie energii per strefa / per maszyna / per zmiana — z rozbiciem na media.
- Intensywność energetyczna (kWh na sztukę wyrobu) — korelacja
dataBi×energyBi. - Raport ISO 50001 — miesięczny, z automatycznym eksportem do PDF i mailem do pełnomocnika systemu zarządzania energią.
- Porównanie zmian / linii / okresów — z testem istotności statystycznej, który łatwo dopisać w SQL.
Wszystko oparte na tej samej parze Data Sources (JSON + Query Results), tylko inne URL-e i inna logika SQL.
Bariery i ograniczenia — uczciwy rachunek
Rozwiązanie jest mocne, ale nie uniwersalne. Kilka rzeczy, o których trzeba wiedzieć przed wdrożeniem:
1. Query Results ma limity rozmiaru
Domyślnie Redash trzyma maksymalnie 1 milion komórek (row × column) w wyniku pojedynczego zapytania cache'owanego pod Query Results. Przy 360 próbkach × 5 kolumn (nasz przykład) to nie jest problem. Przy godzinnym okresie z danych sekundowych z 20 maszyn × 40 kolumn — już tak. Dlatego pierwszym krokiem jest zawsze rozsądne pre-agregowanie w endpoint REST (np. uśrednianie do 30 s na poziomie API), zanim wynik trafi do Query Results.
2. Odświeżanie ma kaskadowy koszt
Każde Query Results SQL czeka, aż bazowe zapytanie się zakończy. Jeśli bazowy endpoint trwa 8 s, a Query Results 2 s — łączny czas to 10 s, nie 2. Dla dashboardu z 12 widgetami oznacza to planowanie refresh schedule tak, żeby bazowe zapytania odświeżały się wcześniej niż te zależne.
3. To nie jest real-time
Typowy refresh co 5–10 minut. Dla MES jest to akceptowalne dla analizy trendu, ale do reaktywnego alarmowania (zatrzymanie linii po wykryciu wibracji poza normą) zawsze używamy osobnej ścieżki — bezpośrednio w backend OmniMES z WebSocket do HMI operatora. Redash jest narzędziem analitycznym, nie kontrolnym.
4. Dialekty SQL
Query Results używa SQLite 3. Jest to świetny dialekt w 90% przypadków, ale brakuje np. natywnego PIVOT, pełnych regexów i zaawansowanych funkcji czasu. Czasem trzeba pisać SQL wielowarstwowo (kaskada Query Results) zamiast w jednym zapytaniu.
5. Bezpieczeństwo
Endpoint REST OmniMES nie może być eksponowany publicznie — musi być wewnątrz zaufanej sieci (VPN, prywatny VLAN, zero-trust service mesh). Redash trzyma cache w swojej bazie metadanych, więc wyniki zapytań także są chronione politykami dostępu Redasha. Dla klientów w sektorze regulowanym (farmacja, energetyka krytyczna) zalecamy dodatkowo SSO (SAML, OIDC) i audit log.
Praktyczne dobre praktyki
Kilka zasad, które wypracowaliśmy w kolejnych wdrożeniach:
- Jedno zapytanie bazowe, wiele pochodnych. Nie rób 15 oddzielnych requestów do API — jeden szeroki endpoint + 15 SQL-i na Query Results. Oszczędność requestów i kosztu infrastruktury.
- Nazewnictwo z prefiksem zakładu.
KLN_vibration_trend,KLN_OEE_per_shift— przy 200 zapytaniach w Redashu to ratuje życie. - Tagi na zapytaniach. Minimum:
raw,agg,viz,dashboard-ready— każdy wie, co jest bazą, a co końcowym widokiem. - Testowanie w środowisku staging. Redash ma tryb "archiwalny" — każda zmiana w zapytaniu zostaje w historii, ale warto mieć osobną instancję staging, żeby nie psuć produkcyjnych dashboardów.
- Dokumentacja w opisie zapytania. Pole "Description" pod zapytaniem — krótki opis co liczy, jakie ma parametry, do czego się nadaje.
Podsumowanie
Dashboardy analityczne na danych z MongoDB bez przepisywania backendu są możliwe — wystarczy REST API jako pierwsza warstwa + Redash Query Results jako druga. Dla OmniMES i OmniEnergy jest to standard w projektach, w których klient potrzebuje custom widoków poza standardowymi dashboardami.
Koszt wdrożenia jest niski: Redash jest open source, integracja z REST API trwa dzień, pierwsze 3–5 dashboardów można zbudować w tygodniu. Korzyść jest wysoka: klient dostaje narzędzie self-service zamiast zależności od zespołu deweloperskiego, a zespół wdrożeniowy może skupić się na właściwej logice biznesowej zamiast na produkcji setek niestandardowych widoków.
W praktyce taka architektura — OmniMES jako system transakcyjny, Redash jako warstwa analityczna — skaluje się znacznie lepiej niż tradycyjny model, w którym każdy nowy raport to nowy ticket dla developera.
Źródła
- Dokumentacja Redash — Query Results Data Source, 2025.
- Dokumentacja Redash — JSON Data Source Handler, 2025.
- MongoDB Inc., Aggregation Framework — Time Series Data, 2025.
- ISO 50001:2018 — Energy management systems.
- Materiały wdrożeniowe OmniMES / OmniEnergy, 2025–2026.